Assaf PinhasiA Simple framework for evaluating ML infra and tooling product ideasimage sourceJun 29Jun 29
Assaf PinhasiinFeature Stores for MLFeature pipelines and feature stores — deep dive into system engineering and analytical tradeoffsIntroductionDec 8, 20221Dec 8, 20221
Assaf PinhasiWhat I’ve learnt about deep work after years of being distractedWhat is deep work?Nov 23, 20221Nov 23, 20221
Assaf PinhasiinTowards Data ScienceFrom raw videos to GAN training — implementing a data pipeline and a lightweight Deep Learning…IntroductionOct 20, 2022Oct 20, 2022
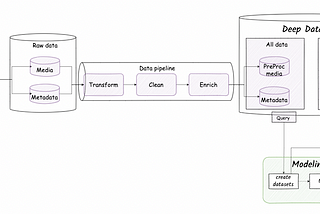
Assaf PinhasiinTowards Data ScienceDeep Lake — an architectural blueprint for managing Deep Learning data at scale — part IIntroductionJun 10, 2022Jun 10, 2022
Assaf PinhasiWhat I’ve learnt from two years of being an expert hands-on technology consultantWhat led me here?Dec 26, 20215Dec 26, 20215
Assaf PinhasiinTowards Data ScienceHow to run CPU-based Workloads for Deep Learning Using Thousands Of Spot Instances on AWS and GCP…Deep learning is notorious for consuming large amounts of GPU resources during training. However, there are multiple parts within the Deep…Jul 26, 2021Jul 26, 2021
Assaf PinhasiinPyTorchA Step by Step Guide to Building A Distributed, Spot-based Training Platform on AWS Using…This is part II of a two-part series, describing our solution for running distributed training on spot instances using TorchElastic and…Jun 29, 2021Jun 29, 2021
Assaf PinhasiinPyTorchHow 3DFY.AI Built a Multi-Cloud, Distributed Training Platform Over Spot Instances with…Deep Learning development is becoming more and more about minimizing the time from idea to trained model.Jun 17, 20213Jun 17, 20213